

Package yang kini populer untuk crawling data twitter adalah twitteR. Tutorialnya berjibun, penggunanya juga sama. Tapi nyatanya tidak hanya twitteR saja yang tersedia package-nya. Ada beberapa aplikasi lain yang kegunaannya sama, salah satunya adalah rtweet.
[AdSense-A]
Kelebihan menggunakan rtweet adalah craling yang dihasilkan langsung berupa data frame, bukan value. Sehingga kita tidak perlu kelelahan memanipulasi data. Selain itu, itu juga perintah untuk mengekspor ke csv, sehingga kita tidak perlu mengistal package xlsx misalnya.
Mula-mula kita harus memasang dan menjalankan package rtweet di R.
install.packages("rtweet")
library("rtweet", lib.loc="~/R/win-library/3.3")
Setting API sedikit berbeda dengan twitteR. kita hanya memasukkan API dan API Secret saja. Nantinya setelah perintah dijalankan kita akan mendirect ke twitter untuk autentifikasi aplikasi.
api <- 'Kode consumer'
apis<-'kode Consumer Secret'
t.token<-create_token(app = "nama aplikasi", api,apis)
Ada berbagai macam perintah yang bisa dijalankan oleh rtweet. Cuma dalam artikel ini kita akan mencoba dua perintah yang populer, yaitu ‘search_tweets’ dan ‘get_timeline’. ‘search_tweets’ digunakan untuk mencari hastag, mention, atau keywords tertentu, sedangkan ‘get_timeline’ digunakan untuk menarik tweets berdasarkan user tertentu.
based <- search_tweets("lipiindonesia", n = 3000, token = t.token)
view(based)
Hasilnya akan muncul data seperti dibawah ini.
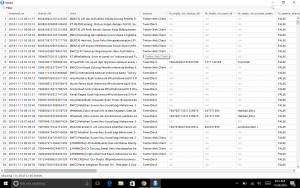
Begitu pula dengan get_timeline, kita bisa menjalankan perintahnya dengan contoh seperti ini
basedr<-get_timeline('lipiindonesia', n = 5000)
Dari 5000 data yang diminta, dikembalikan sebanyak 3195. Lumayan banyak hemat saya. Entah mengapa ketika menggunakan twitteR, dengan token dan keyword yang sama, rtweet menghasilkan crawling yang lebih banyak. Mungkin cuma kebetulan.
Leave a Reply